Time spent: 2.5h
Total: 16h/10000h
I feel like gradient descent is where ML models start to get interesting. Like, how do the models actually adapt to the data? We’ll look into that now. First, it’ll be helpful to cover a bit of math to understand the algorithm fully.
Partial Derivatives
The partial derivative of a function with respect to some variable , denoted , is a bit like the normal derivative, just that it’s used in multivariable functions. The principle is really simple actually:
- Assume all the other variables were constant, and
- differentiate with respect to as if it were a single-variable function.
That’s it.
Example 1: Given , find and .
Solution:
- : Treat as constant: .
- : Treat as constant: .
Gradient Descent
Gradient descent is a fundamental optimization algorithm used very widely in machine learning models. The point is essentially to try to minimize the value of the cost function by making small adjustments to the parameters. It uses partial derivatives under the hood to minimize using its’ gradient. Let’s look a bit into how this is done:
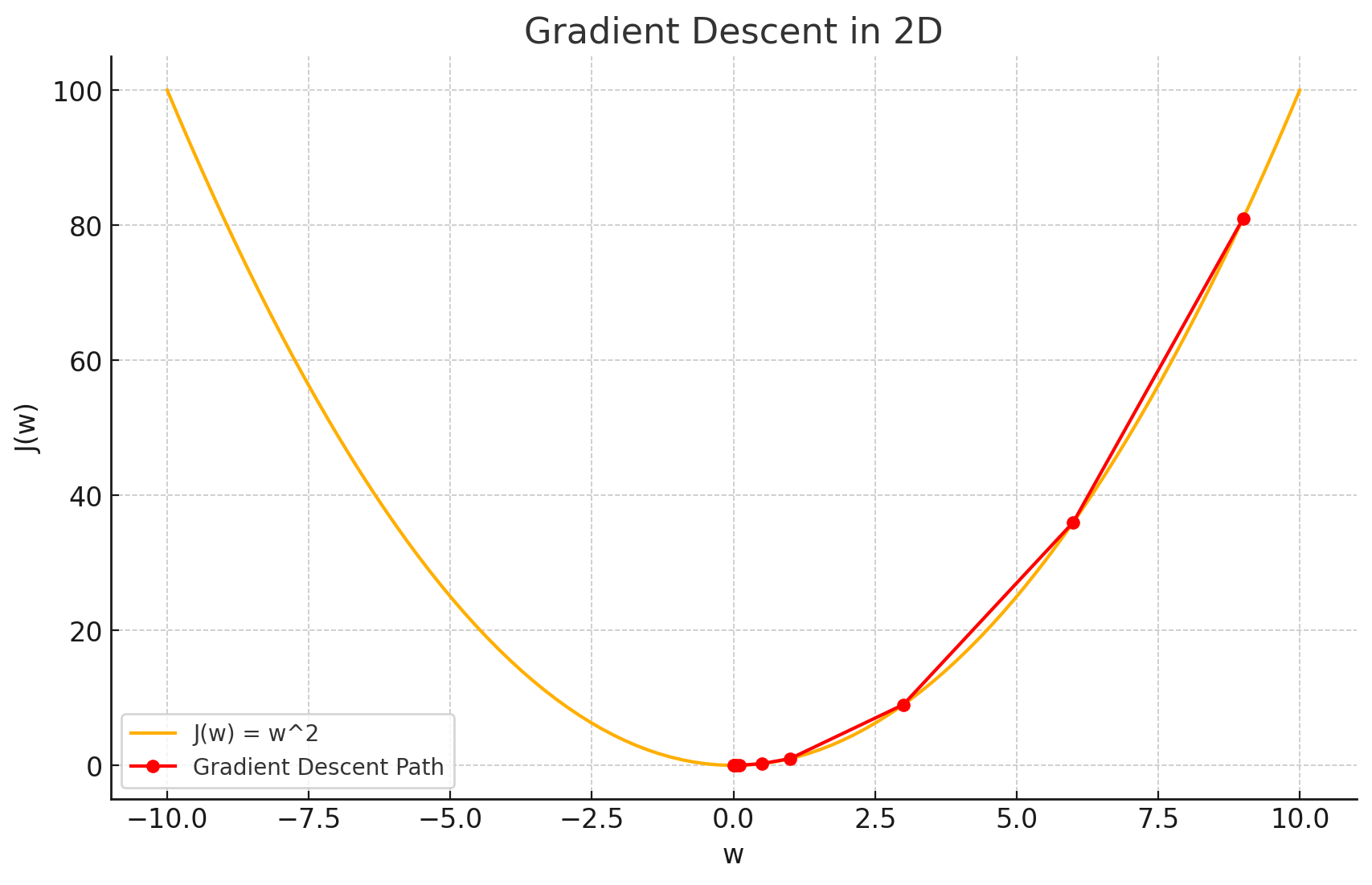
Gradient descent visualization in 2D. (ChatGPT/matplotlib)
Essentially gradient descent finds the slope of the cost function , and adjusts the parameter slightly (in relation to the slope) so that the value of starts going down, step-by-step. Gradient descent requires the function to be convex — which means that the function must always be curving upwards — for example, a parabola. Note the example only has the parameter here. Let’s add a dimension and see what happens if we also add the parameter :
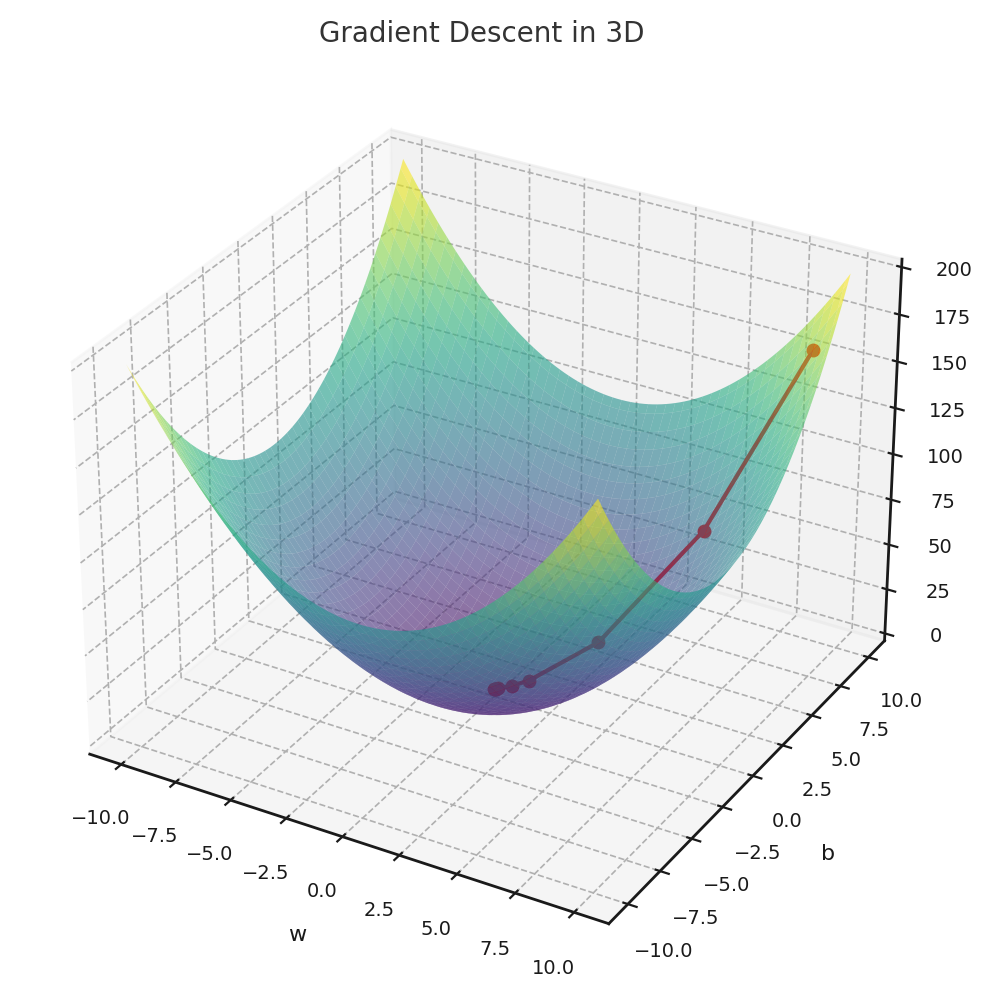
Gradient descent visualization in 3D. (ChatGPT/matplotlib)
So, the principle still says the same. It’s going to be slightly harder to visualize when we have a vector of weights, though.
Let’s take the mean squared error (MSE) cost function we went over previously. Recall:
Let’s use it in our example of linear regression, where we have features and weights . Note we use to describe the number of features. We’ll hence use to describe the number of training examples. Now our cost function becomes
Wait. Why is it instead of ? Well, the explanation is that it slightly simplifies the computation of the gradient. See, the partial derivative with respect to some parameter, let’s say (the weight parameter of the :th feature of every training example) of the cost function when using simplifies to:
where is the weight for the :th feature of the :th training example. The notation is often used to describe the :th feature of the input vector, and I think it makes this example a bit easier to understand. Anyway — when we divide the cost function by , it will instead simplify to
which makes it slightly nicer. That right there is the slope of the function that gradient descent tries to use to start approaching a smaller value.
Here’s roughly how the algorithmic part of gradient descent works:
- Initialize the parameters and to some arbitrary values.
- Compute the gradient of the cost function with respect to .
- Adjust slightly with respect to the gradient.
- Compute the gradient of the cost function with respect to .
- Adjust slightly with respect to the gradient.
- Repeat steps 2-5 until the value of the cost function has converged to a sufficiently small value.
Note that the parameters must be adjusted separately. You cannot compute both and first and only adjust after, since this would mess with the result.
Let’s introduce a new variable — the learning rate . It’s used to control how large the step of a gradient descent is, and it’s often set to some really small value, like . Why is it needed? Well, see what happens when gradient descent tries to take steps too big:
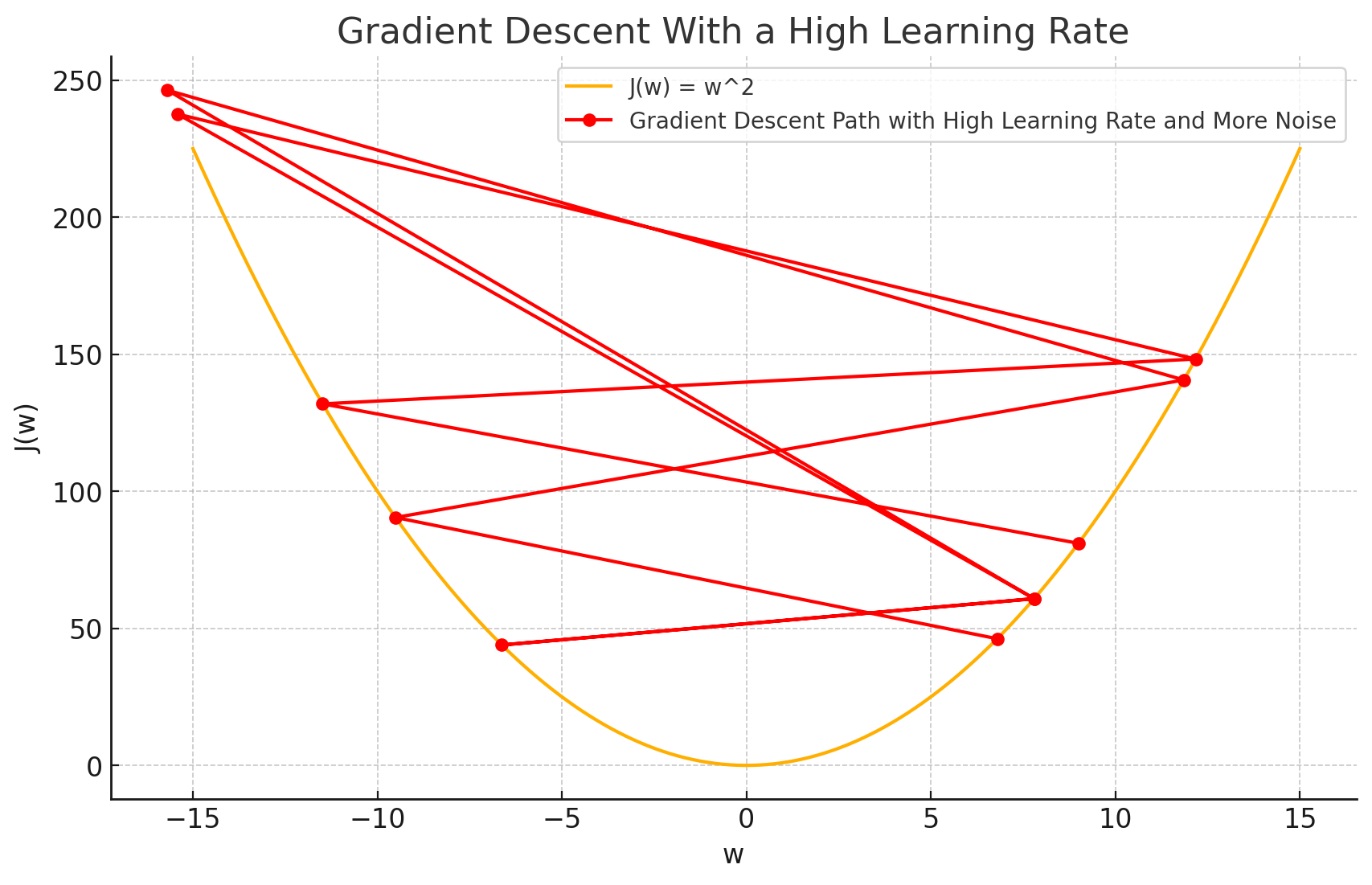
Gradient descent with a learning rate too high. (ChatGPT/matplotlib)
The function starts oscillating instead of converging nicely! It tries to jump so far that it ends up increasing the cost — drastically.
Anyway, with the learning rate, the parameter updates look like this:
Let’s implement this in code for the linear regression program we wrote earlier.
# arbitrary values
w = 1
b = -2
...
# the number of total iterations over the dataset
epochs = 100
m = len(X)
# learning rate
lr = 0.000001
for _ in range(epochs):
w_grad = 0
b_grad = 0
# compute gradient for w
for i in range(m):
w_grad += (loss(w, b, X.iloc[i], Y.iloc[i])) * X.iloc[i]
w_gradient = w_grad / m
w -= lr * w_gradient
# compute gradient for b
for i in range(m):
b_grad += (loss(w, b, X.iloc[i], Y.iloc[i]))
b_gradient = b_grad / m
b -= lr * b_gradient
print(mse(w, X, b, Y))
>>>print(w, b)
1079.4370200437074 -3.825167863903606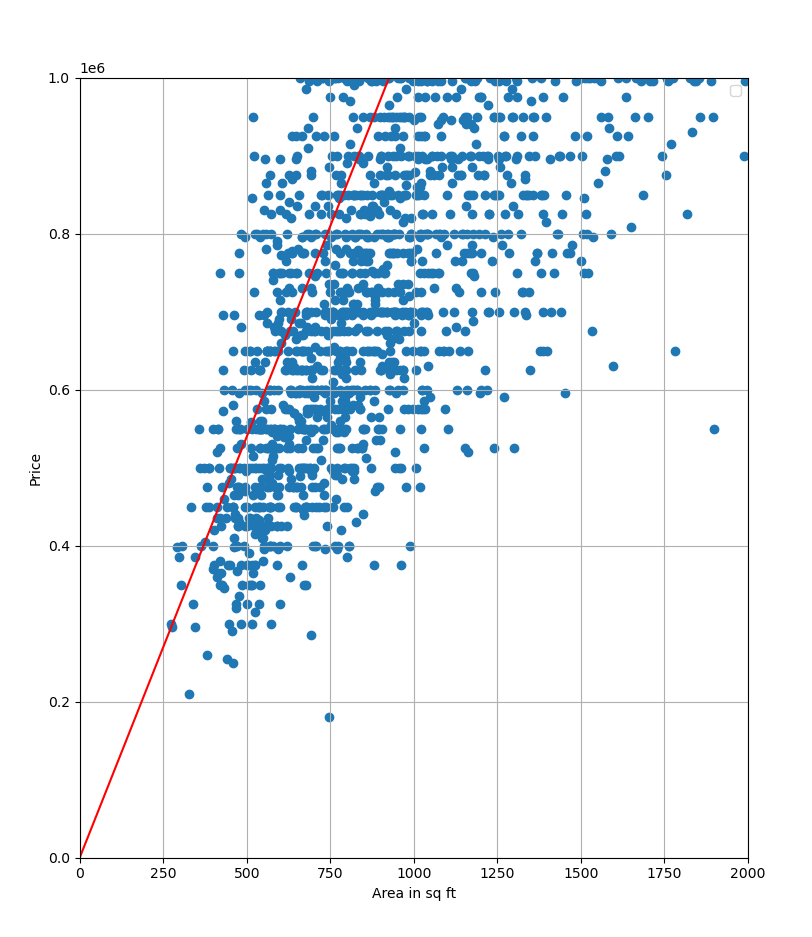
The optimal fit.
Looks like we found the optimal fit! The MSE value is still very high due to the nature of the dataset, but let’s not let that distract us. Now that I look back, a simpler dataset would’ve definitely been better to illustrate my points haha. Well, I decided to go with a real-world dataset instead.
I’ll be reimplementing gradient descent for multiple linear regression later, when I look at numpy and vectorization.